※ PostgreSQL: EXPLAIN.
안녕하세요. 듀스트림입니다.
오늘은 성능 최적화의 시작인 EXPLAIN에 대해 알아보겠습니다.
1. EXPLAIN?
PostgreSQL의 EXPLAIN은 쿼리 실행 전에 플래너가 수립한 실행 계획을 보여주는 명령어입니다
EXPLAIN ANALYZE는 실제로 쿼리를 실행한 후 통계를 함께 출력합니다.
실행계획을 해석하는 것은 성능 최적화의 출발점이며, 단순한 실행 경로 확인을 넘어서 통계 정보의 신뢰도와 인덱스의 효율성까지 진단하는 데 도움이 됩니다.
EXPLAIN
EXPLAIN EXPLAIN — show the execution plan of a statement Synopsis EXPLAIN [ ( option [, ...] ) ] statement …
www.postgresql.org
14.1. Using EXPLAIN
14.1. Using EXPLAIN # 14.1.1. EXPLAIN Basics 14.1.2. EXPLAIN ANALYZE 14.1.3. Caveats PostgreSQL devises a query plan for each query it …
www.postgresql.org
2. 실행계획의 구성 요소
기본 항목 설명 표
| 항목 | 설명 |
| Node Type | 실행 계획의 노드 유형 (예: Seq Scan, Index Scan, Nested Loop, Hash Join 등) |
| Startup Cost / Total Cost | 첫 번째 결과 행까지의 예상 비용 / 전체 결과 반환까지의 총 예상 비용 |
| Rows | PostgreSQL 옵티마이저가 예측한 예상 반환 행 수 |
| Actual Time | EXPLAIN ANALYZE 시 기록되는 실제 실행 시간 (ms 단위) |
| Actual Rows | 실제로 반환된 행 수. 예측 값과 차이가 크면 통계 정보 부정확 가능성 있음 |
| Loops | 해당 노드가 반복 실행된 횟수. 상위 루프에 따라 곱해진 누적 실행 수를 의미 |
| Index Cond | 인덱스를 이용해 필터링할 수 있는 조건 (효율적 처리 가능) |
| Filter | 인덱스 외의 조건 필터링 (비용이 상대적으로 높음) |
주요 Node Type 종류
| Node Type | 설명 |
| Seq Scan | 테이블을 처음부터 끝까지 순차적으로 스캔함. 인덱스가 없거나 플래너가 효율적이라고 판단할 때 사용됨 |
| Index Scan | 인덱스를 통해 조건에 해당하는 행만 조회. 조건절에 인덱스가 적절히 적용되어야 유도 가능 |
| Index Only Scan | 인덱스만으로 필요한 데이터를 모두 조회 가능할 때. 테이블 접근 없이 인덱스만으로 처리 |
| Bitmap Index Scan | 조건에 부합하는 행의 위치만 수집 후, 테이블에서 해당 위치의 데이터를 조회함 (다건 처리 효율적) |
| Bitmap Heap Scan | Bitmap Index Scan과 함께 사용되어 실제 테이블 데이터를 가져오는 작업 수행 |
| Nested Loop | 한쪽 테이블의 행마다 다른 쪽 테이블을 반복해서 스캔. 소규모 테이블이나 인덱스가 있을 때 유리함 |
| Hash Join | 한 테이블을 해시 테이블로 변환하여 다른 테이블과 매칭. 중간 크기 이상의 조인에 적합 |
| Merge Join | 양쪽 테이블이 정렬되어 있거나 인덱스를 통해 정렬되어 있는 경우 효율적 |
| Aggregate | SUM, COUNT, AVG 등 집계 연산 처리. GROUP BY, HAVING 구문 포함 시 자주 등장 |
| Sort | 결과 정렬 처리. work_mem 설정에 따라 메모리/디스크 사용 여부 결정 |
| Limit | 지정된 수만큼 결과를 제한. 효율적인 실행 중단 처리 가능 |
관련 소스 코드: execProcnode.c, /optimizer/plan
3. 실행계획 해석 순서
실행계획은 트리 형태로 출력되며, 이를 분석할 때는 위에서 아래로, 왼쪽에서 오른쪽으로 순차적으로 따라가며 각 노드를 읽는 것
이 일반적인 절차입니다.
각 노드는 하위 연산(스캔, 조인 등)을 먼저 실행하고 상위 노드로 데이터를 전달하는 구조입니다.
다음은 실행계획 해석 시 따라야 할 분석 단계입니다.
A [루트 노드 파악 (Aggregate, Sort 등)] --> B [하위 노드로 이동]
B --> C [스캔 방식 확인 (Seq Scan, Index Scan 등)]
C --> D [조인 방식 분석 (Nested Loop, Hash Join 등)]
D --> E [조건절 적용 위치 확인]
E --> F [예상 Rows vs Actual Rows 비교]
F --> G [실행 시간 및 반복 횟수 확인]
실행계획 트리에서 각 노드는 ->로 연결됩니다.
이는 부모-자식 관계를 나타내며, 데이터가 어떤 연산 결과에서 상위 연산으로 전달되는지를 시각적으로 보여줍니다.
예를 들어 -> Seq Scan은 상위 노드가 Seq Scan의 결과를 입력으로 사용함을 의미합니다.
• 읽을 때는 들여쓰기와 함께 이 화살표 방향을 기준으로 하위 노드를 먼저 해석해야 실행 순서를 이해할 수 있습니다.
• 이 표현은 PostgreSQL의 EXPLAIN 텍스트 출력 방식에서 중요한 시각적 힌트입니다.
- 루트 노드 파악
- 계획의 최상단 노드는 쿼리의 최종 작업을 나타냅니다.
- 예를 들어 집계 쿼리는 Aggregate, 정렬된 결과를 반환하는 쿼리는 Sort, 서브쿼리는 Subquery Scan 등의 노드로 시작됩니다.
- 하위 노드 추적
- 루트 노드 아래로 내려가면서 실제 데이터를 가져오는 방식(스캔 또는 조인 등)을 파악합니다.
- 이 때 노드의 Node Type을 기준으로 접근 방식을 분류합니다.
- 스캔 방식 확인
- 테이블 접근 방식이 Seq Scan인지, Index Scan 또는 Bitmap Index Scan인지 확인합니다.
- 인덱스를 사용하지 않고 전체 테이블을 순차적으로 스캔할 경우 튜닝 여지가 있습니다.
- 조인 방식 분석
- Nested Loop, Hash Join, Merge Join의 사용 여부와 조인 순서에 따라 쿼리 성능이 달라집니다.
- 각 방식은 입력 테이블의 크기, 정렬 여부, 인덱스 유무 등에 따라 선택됩니다.
- 조건절 적용 위치
- Index Cond는 인덱스가 직접 조건을 처리할 수 있는 경우 나타나며, 효율적입니다.
- Filter는 테이블에서 데이터를 읽은 후 적용되므로, 상대적으로 비용이 큽니다.
- 예측과 실제의 차이 분석
- Rows, Actual Rows가 크게 차이난다면 통계 정보(pg_statistic)가 오래되었거나 부정확할 수 있습니다.
- Actual Time, Loops 등을 통해 어느 노드에서 병목이 발생했는지 확인합니다.
+ 실행계획의 실제 실행 순서 이해
읽는 순서와 달리, PostgreSQL 실행계획의 실제 실행은 하위 노드(리프)부터 시작됩니다.
| 구분 | 설명 |
| 읽는 순서 | 실행계획의 트리 상단부터 하단(루트 → 리프)으로 읽으며, 쿼리의 논리적 흐름을 파악 |
| 실행 순서 | 실제 실행은 가장 하단의 스캔 노드부터 시작하여, 데이터를 위쪽 노드로 전달하며 가공 처리 |
예를 들어 아래 실행계획을 확인해 보겠습니다.
EXPLAIN ANALYZE SELECT COUNT(*) FROM a WHERE age > 50;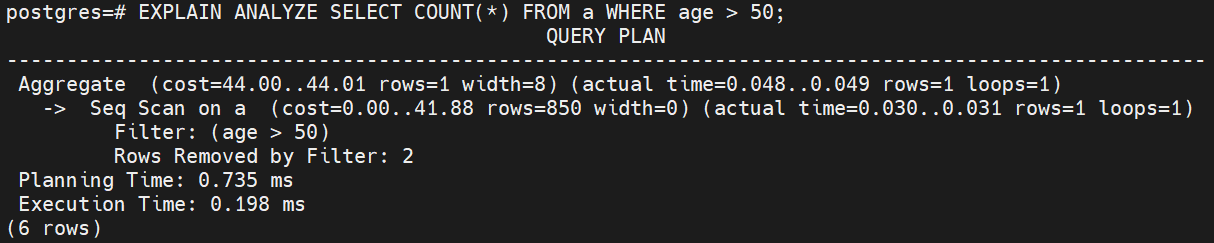
- 실행 흐름
- Seq Scan 노드에서 테이블 a를 순차적으로 스캔하며 age > 50 조건 필터링
- 필터링된 결과를 Aggregate 노드로 전달하여 COUNT 수행
실제 실행은 리프 노드부터 상위 노드로 올라가는 방식으로 이뤄지며, 이 흐름은 PostgreSQL의 executor 내부에서 제어됩니다.
관련 소스 코드: execProcnode.c
4. 예제
데이터 셋 생성
테이블 생성
CREATE TABLE a (
id SERIAL PRIMARY KEY,
name TEXT,
age INT,
created_at TIMESTAMP DEFAULT NOW()
);
CREATE TABLE b (
id SERIAL PRIMARY KEY,
a_id INT REFERENCES a(id),
score INT
);
CREATE TABLE c (
id SERIAL PRIMARY KEY,
b_id INT REFERENCES b(id),
tag TEXT,
created_at TIMESTAMP DEFAULT NOW()
);
데이터 삽입
INSERT INTO a (name, age)
SELECT 'name_' || i, (random()*100)::INT FROM generate_series(1, 100000) i;
INSERT INTO b (a_id, score)
SELECT (random()*99999)::INT + 1, (random()*100)::INT FROM generate_series(1, 200000);
INSERT INTO c (b_id, tag)
SELECT (random()*199999)::INT + 1, 'tag_' || (i % 100) FROM generate_series(1, 300000) i;
인덱스 생성
CREATE INDEX idx_b_aid ON b(a_id);
CREATE INDEX idx_c_b_id ON c(b_id);
CREATE INDEX idx_c_tag ON c(tag);Case 1: 인덱스가 없는 쿼리
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM a WHERE name = 'name_9999';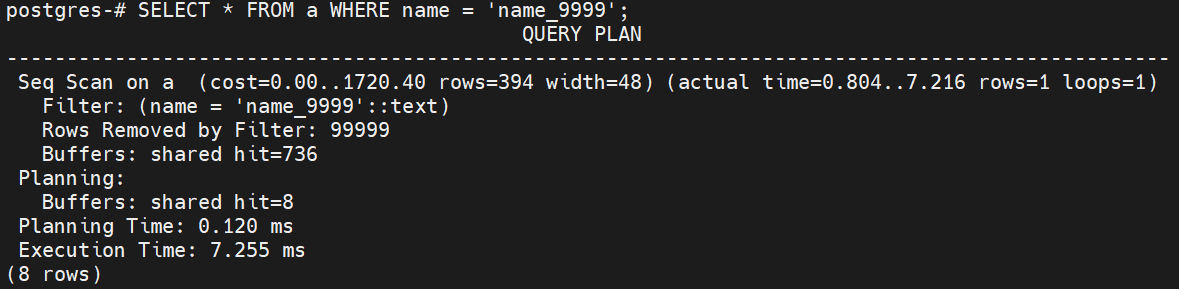
흐름
- a 테이블을 순차적으로 스캔하며 name = 'name_9999' 필터를 적용합니다.
- Seq Scan에서 조건을 만족하는 데이터를 필터링하여 최종 결과로 반환합니다.
실행계획 분석
- Seq Scan 노드:
- 목적: a 테이블에서 모든 데이터를 순차적으로 읽어옵니다.
- 동작: 테이블을 한 행씩 순차적으로 읽으며, name = 'name_9999'라는 조건을 필터링하여 해당 조건을 만족하는 행만 반환합니다.
- 비용: cost=0.00..1986.00
- 0.00: 쿼리 시작 시 예상되는 비용
- 1986.00: 테이블 전체를 스캔하는 데 소요될 예상 비용
- 실제 시간: actual time=0.907..6.775
- 0.907 ms: 스캔을 시작한 시점에서 첫 번째 행을 읽는 데 걸린 시간
- 6.775 ms: 쿼리가 종료될 때까지 전체 실행에 걸린 시간
- 행 수: rows=1
- 최종적으로 조건을 만족하는 행은 1개가 반환되었습니다.
- 제거된 행 수: Rows Removed by Filter: 99999
- 필터 조건에 맞지 않는 99999개의 행은 제거되었습니다.
- 버퍼 사용: shared hit=736
- 736개의 데이터 페이지가 메모리에서 히트되었습니다. (해당 데이터가 디스크에서 다시 읽어지지 않고 메모리에서 처리되었음을 나타냅니다.)
- Planning
- 버퍼 사용: shared hit=3 dirtied=1
- 쿼리 계획을 수립할 때 3개의 페이지가 공유 버퍼에서 히트되었으며, 1개의 페이지는 수정되어 디스크에 기록되었습니다.
- Planning Time: 0.187 ms
- 쿼리 계획을 생성하는 데 걸린 시간은 0.187ms입니다.
- 버퍼 사용: shared hit=3 dirtied=1
- Execution Time: 6.793 ms
- 전체 쿼리 실행에 소요된 시간은 약 6.793ms입니다.
Case 2: 인덱스가 있는 쿼리
EXPLAIN (ANALYZE, BUFFERS)
SELECT * FROM c WHERE tag = 'tag_77';
흐름
- Bitmap Index Scan (리프 노드)
- idx_c_tag 인덱스를 사용하여 tag = 'tag_77' 조건을 만족하는 행들의 위치를 찾습니다.
- 조건을 만족하는 3000개의 행을 찾습니다.
- Bitmap Heap Scan (루트 노드)
- Bitmap Index Scan에서 찾은 위치 정보를 바탕으로 실제 데이터를 읽어옵니다.
- tag = 'tag_77' 조건을 재확인하고, 3000개의 행을 반환합니다.
- 결과 반환
- 최종적으로 조건을 만족하는 3000개의 행이 반환됩니다.
실행계획 분석
- Bitmap Index Scan (리프 노드)
- 목적: idx_c_tag 인덱스를 사용하여 tag = 'tag_77' 조건을 만족하는 행을 빠르게 찾습니다.
- 동작: 인덱스를 사용하여 조건을 만족하는 행들의 위치를 찾고, 그 위치 정보를 Bitmap 형태로 기록합니다.
- 비용: cost=0.00..34.92
- 0.00: 인덱스 스캔을 시작하는 비용
- 34.92: 인덱스를 사용하여 해당 조건을 찾는 데 드는 비용
- 실제 시간: actual time=0.938..0.939
- 0.938 ms: 인덱스 검색을 시작한 시점에서 첫 번째 결과를 찾는 데 걸린 시간
- 0.939 ms: 인덱스 검색을 완료하는 데 걸린 시간
- 행 수: rows=3000
- 3000개의 행이 조건을 만족한다고 추정됩니다.
- 버퍼 사용: shared hit=6
- 인덱스 스캔 중 6개의 페이지가 메모리에서 히트되었습니다. 이 데이터는 디스크에서 다시 읽지 않고 메모리에서 처리되었습니다.
- Bitmap Heap Scan (루트 노드)
- 목적: Bitmap Index Scan에서 찾은 위치 정보를 바탕으로 실제 데이터(힙)를 읽어옵니다.
- 동작: Bitmap Index Scan에서 제공한 위치 정보대로 힙 데이터를 읽고, tag = 'tag_77' 조건을 재확인합니다.
- 비용: cost=35.67..2067.38
- 35.67: Bitmap Index Scan으로 찾은 데이터 위치를 기반으로 힙을 읽는 비용
- 2067.38: 전체 힙을 읽는 데 소요될 예상 비용
- 실제 시간: actual time=1.279..5.628
- 1.279 ms: Bitmap Index Scan에서 제공된 정보를 바탕으로 첫 번째 힙 데이터를 읽는 데 걸린 시간
- 5.628 ms: 전체 힙 데이터 읽기와 조건 재확인까지 걸린 시간
- 행 수: rows=3000
- 3000개의 행이 실제로 반환되었습니다.
- Heap Blocks: exact=1911
- 1911개의 정확한 힙 블록이 사용되었습니다. 즉, 이 데이터들이 실제로 메모리에서 읽혔습니다.
- 버퍼 사용: shared hit=1917
- 1917개의 데이터 페이지가 메모리에서 히트되었습니다. 이 데이터는 디스크에서 다시 읽지 않고 메모리에서 처리되었습니다.
- Planning
- 버퍼 사용: shared hit=6 dirtied=0
- 쿼리 계획을 수립할 때 6개의 페이지가 공유 버퍼에서 히트되었으며, 수정된 페이지는 없습니다.
- Planning Time: 0.430 ms
- 쿼리 계획을 생성하는 데 걸린 시간은 0.430 ms입니다.
- 버퍼 사용: shared hit=6 dirtied=0
- Execution Time: 5.892 ms
- 전체 쿼리 실행에 소요된 시간은 약 5.892 ms입니다.
Case 3: Hash Join vs Nested Loop Join
- Hash Join
EXPLAIN ANALYZE
SELECT a.id, b.score
FROM a
JOIN b ON a.id = b.a_id
WHERE a.age < 30;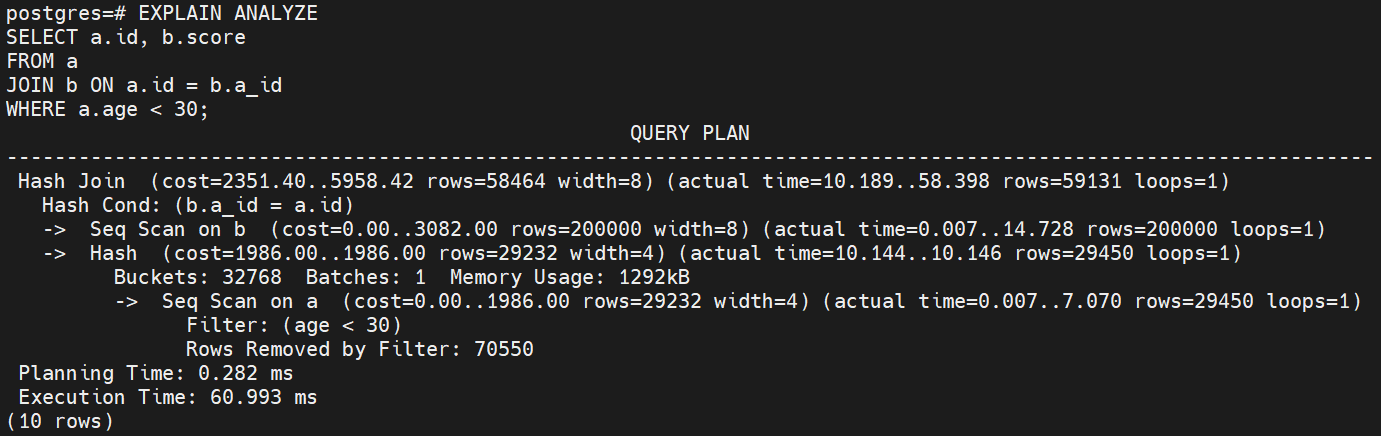
흐름
- Seq Scan on a (리프 노드)
- a 테이블을 순차적으로 스캔하고 age < 30 조건을 만족하는 행을 필터링하여 29450개의 행을 반환합니다.
- Seq Scan on b (리프 노드)
- b 테이블을 순차적으로 스캔하고 a.id = b.a_id 조건을 만족하는 행을 찾습니다.
- 이때, b 테이블에서 200000개의 행을 검색합니다.
- Hash (리프 노드)
- a 테이블에서 age < 30 조건을 만족하는 데이터를 해시 테이블로 변환하여 b.a_id = a.id 조건을 효율적으로 찾을 수 있게 준비합니다.
- Hash Join (루트 노드)
- b 테이블에서 읽어온 각 행을 a 테이블에서 만든 해시 테이블과 결합하여 a.id = b.a_id 조건을 만족하는 행을 찾고 결합합니다.
- 최종적으로 59131개의 행을 반환합니다.
- 결과 반환
- 최종적으로 a.id와 b.score를 포함하는 59131개의 행이 반환됩니다.
실행계획 분석
- Seq Scan on a (리프 노드)
- 목적: a 테이블에서 age < 30 조건을 만족하는 데이터를 순차적으로 읽어옵니다.
- 동작: a 테이블을 순차적으로 읽고, age < 30 조건을 적용하여 해당 조건을 만족하는 행만 반환합니다.
- 비용: cost=0.00..1986.00
- 0.00: 쿼리 시작 시 예상되는 비용
- 1986.00: 테이블 전체를 스캔하는 데 소요될 예상 비용
- 실제 시간: actual time=0.007..7.070
- 0.007 ms: Seq Scan을 시작한 후 첫 번째 행을 읽는 데 걸린 시간
- 7.070 ms: Seq Scan이 완료되고, 전체 데이터를 읽는 데 걸린 시간
- 행 수: rows=29450
- 29450개의 행이 age < 30 조건을 만족합니다.
- 제거된 행 수: Rows Removed by Filter: 70550
- 70550개의 행은 age < 30 조건을 만족하지 않아 제거되었습니다.
- Seq Scan on b (리프 노드)
- 목적: b 테이블을 순차적으로 읽고, b.a_id = a.id 조건에 맞는 데이터를 찾습니다.
- 동작: a 테이블의 각 행에 대해 b.a_id = a.id 조건에 맞는 행을 찾기 위해 b 테이블을 스캔합니다.
- 비용: cost=0.00..3082.00
- 0.00: 쿼리 시작 시 예상되는 비용
- 3082.00: b 테이블을 전부 스캔하는 데 소요될 예상 비용
- 실제 시간: actual time=0.007..14.728
- 0.007 ms: Seq Scan을 시작한 후 첫 번째 행을 읽는 데 걸린 시간
- 14.728 ms: Seq Scan이 완료되고, 전체 데이터를 읽는 데 걸린 시간
- 행 수: rows=200000
- 200000개의 행이 반환되었습니다.
- Hash (리프 노드)
- 목적: a 테이블의 데이터를 해시 테이블로 변환하여 b.a_id = a.id 조건을 효율적으로 찾을 수 있도록 준비합니다.
- 동작: a 테이블에서 조건에 맞는 데이터를 해시 테이블로 변환하여, 나중에 b 테이블과 결합할 때 빠르게 조인할 수 있도록 합니다.
- 비용: cost=1986.00..1986.00
- 이 단계에서 소요될 비용은 주로 a 테이블에서 데이터를 해시 테이블로 만드는 비용입니다.
- 실제 시간: actual time=10.144..10.146
- 해시 테이블을 준비하는 데 소요된 시간은 0.002 ms 정도입니다.
- 버킷 수: Buckets: 32768
- 32768개의 버킷을 사용하여 해시 테이블을 만듭니다.
- 메모리 사용: Memory Usage: 1292kB
- 해시 테이블에 사용된 메모리는 약 1.3MB입니다.
- Hash Join (루트 노드)
- 목적: b.a_id = a.id 조건에 맞는 행들을 해시 조인을 사용하여 결합합니다.
- 동작: b 테이블에서 읽어온 행들을 a 테이블에서 만든 해시 테이블과 비교하여, 조건을 만족하는 행을 결합합니다.
- 비용: cost=2351.40..5958.42
- 2351.40: Seq Scan과 Hash 생성 후 b 테이블에서 데이터를 읽어오는 데 드는 비용
- 5958.42: 전체 해시 조인 결과를 반환하는 데 드는 예상 비용
- 실제 시간: actual time=10.189..58.398
- 10.189 ms: 해시 조인 시작 시점에서 첫 번째 결합된 행을 반환하는 데 걸린 시간
- 58.398 ms: 전체 조인 작업 완료까지 걸린 시간
- 행 수: rows=59131
- 최종적으로 59131개의 행이 반환되었습니다.
- Planning
- Planning Time: 0.282 ms
- 쿼리 계획을 수립하는 데 걸린 시간은 0.282 ms입니다.
- Planning Time: 0.282 ms
- Execution Time: 60.993 ms
- 전체 쿼리 실행에 소요된 시간은 약 60.993 ms입니다.
- Nested Loop Join
-- NL 유도
SET enable_hashjoin = off;
SET enable_mergejoin = off;
EXPLAIN ANALYZE
SELECT a.id, b.score
FROM a
JOIN b ON a.id = b.a_id
WHERE a.age < 30;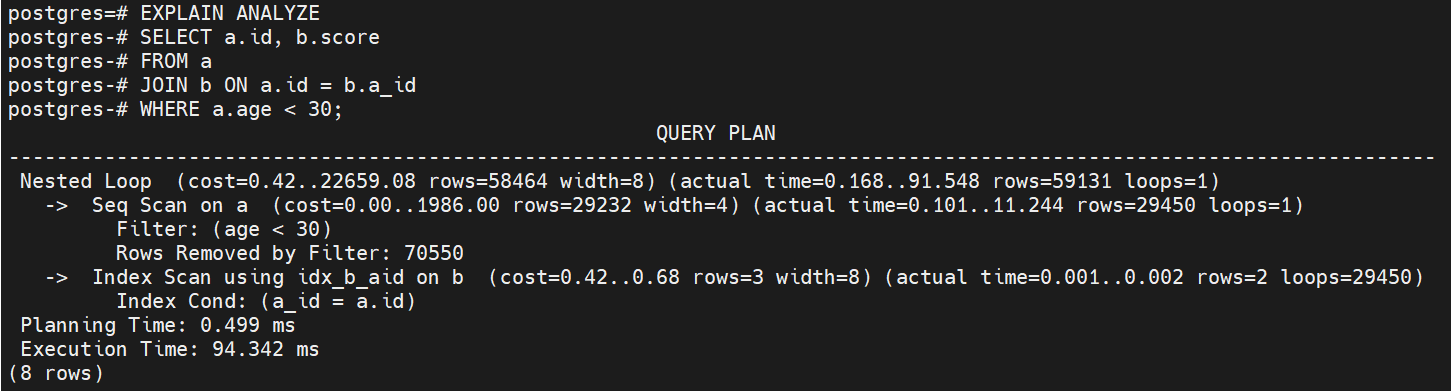
흐름
- Seq Scan (리프 노드)
- a 테이블에서 age < 30 조건을 만족하는 데이터를 순차적으로 스캔합니다.
- 29450개의 행을 반환하고, 조건을 만족하지 않는 70550개의 행은 제거됩니다.
- Index Scan (리프 노드)
- b 테이블에서 a.id와 일치하는 b.a_id 값을 찾기 위해 인덱스를 사용합니다.
- a.id와 일치하는 b.a_id를 찾는 데 인덱스를 활용하여 효율적으로 검색합니다.
- Nested Loop:
- Seq Scan에서 반환된 각 행에 대해 Index Scan을 반복하여 일치하는 데이터를 찾습니다.
- 최종적으로 59131개의 행을 반환합니다.
- 결과 반환:
- Seq Scan과 Index Scan을 결합하여 조건을 만족하는 데이터 59131개를 반환합니다.
실행계획 분석
- Seq Scan 노드 (리프 노드)
- 목적: a 테이블에서 age < 30 조건을 만족하는 데이터를 순차적으로 읽어옵니다.
- 동작: a 테이블을 순차적으로 읽고, age < 30 필터를 적용하여 조건을 만족하는 행만 반환합니다.
- 비용: cost=0.00..1986.00
- 0.00: 쿼리 시작 시 예상되는 비용
- 1986.00: 테이블 전체를 스캔하는 데 소요될 예상 비용
- 실제 시간: actual time=0.101..11.244
- 0.101 ms: Seq Scan을 시작한 후 첫 번째 행을 읽는 데 걸린 시간
- 11.244 ms: Seq Scan이 완료되고, 전체 데이터를 읽는 데 걸린 시간
- 행 수: rows=29450
- 29450개의 행이 age < 30 조건을 만족합니다.
- 제거된 행 수: Rows Removed by Filter: 70550
- 70550개의 행은 age < 30 조건을 만족하지 않아 제거되었습니다.
- Index Scan (리프 노드)
- 목적: b 테이블에서 a_id = a.id 조건을 만족하는 데이터를 찾기 위해 인덱스를 사용합니다.
- 동작: a 테이블에서 읽어온 각 행에 대해, b 테이블의 인덱스(idx_b_aid)를 사용하여 a.id와 일치하는 b.a_id 값을 찾습니다.
- 비용: cost=0.42..0.68
- 0.42: 인덱스를 사용하여 b 테이블에서 조건을 찾는 데 드는 예상 비용
- 0.68: 인덱스를 통해 b 테이블에서 해당 데이터를 찾는 전체 예상 비용
- 실제 시간: actual time=0.001..0.002
- 각 인덱스 스캔에서 조건을 만족하는 행을 찾는 데 걸린 시간은 약 0.001 ms에서 0.002 ms로 매우 빠릅니다.
- 행 수: rows=2 (각 a.id에 대해 b에서 2개의 행이 반환됨)
- 반복 횟수: loops=29450
- a 테이블에서 29450번 Seq Scan을 수행할 때마다 Index Scan이 반복됩니다.
- Nested Loop
- 목적: Seq Scan에서 반환된 각 행에 대해, Index Scan을 실행하여 a.id와 b.a_id가 일치하는 행을 찾습니다.
- 동작: Seq Scan이 반환한 각 행에 대해 b 테이블을 조회하여 조건을 만족하는 값을 찾습니다.
- 비용: cost=0.42..22659.08
- 0.42: Index Scan의 초기 비용
- 22659.08: 전체 Seq Scan과 관련된 비용을 포함한 예상 비용
- 실제 시간: actual time=0.168..91.548
- 전체 실행 시간 동안 0.168 ms부터 91.548 ms까지 걸렸습니다.
- 행 수: rows=59131
- 최종적으로 59131개의 행이 결과로 반환됩니다.
- Planning
- Planning Time: 0.499 ms
- 쿼리 계획을 수립하는 데 걸린 시간은 0.499 ms입니다.
- Planning Time: 0.499 ms
- Execution Time: 94.342 ms
- 전체 쿼리 실행에 소요된 시간은 약 94.342 ms입니다.
Case 4: 서브쿼리 vs LATERAL
- 서브쿼리
EXPLAIN ANALYZE
SELECT a.name, (SELECT MAX(score) FROM b WHERE a_id = a.id)
FROM a WHERE id < 1000;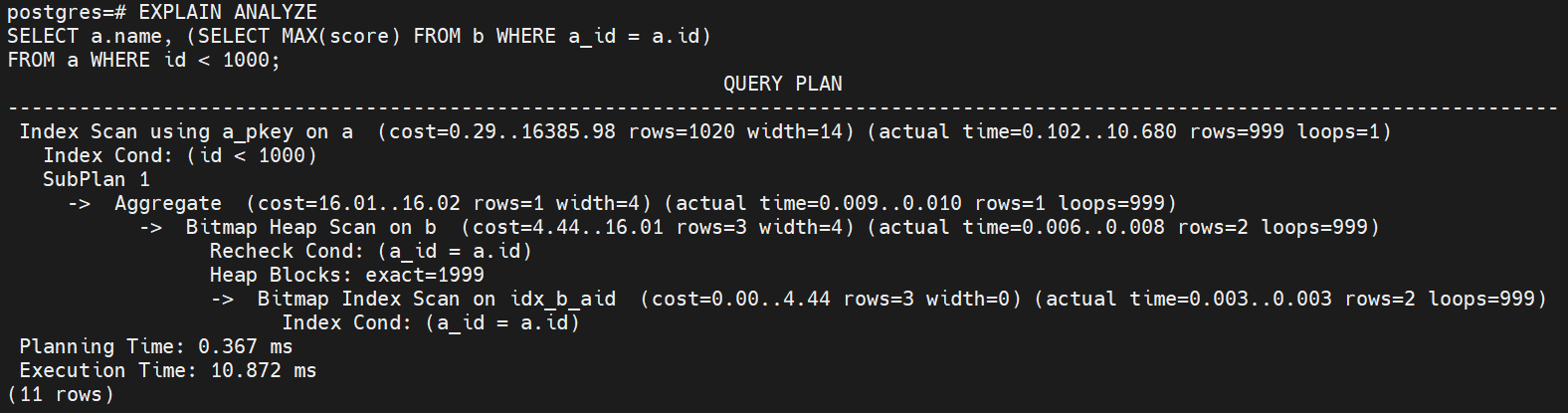
흐름
- Index Scan on a (리프 노드)
- a_pkey 인덱스를 사용하여 a.id < 1000 조건을 만족하는 행을 빠르게 찾습니다.
- 999개의 행이 조건을 만족하는 결과로 반환됩니다.
- SubPlan 1 (서브쿼리)
- 각 a.id에 대해 서브쿼리를 실행하여 b.a_id = a.id 조건에 맞는 데이터를 찾고, MAX(score) 값을 계산합니다.
- Bitmap Index Scan on b (리프 노드)
- b 테이블에서 a.id와 일치하는 b.a_id 값을 찾기 위해 인덱스를 사용합니다.
- 인덱스 검색으로 2개의 행을 찾습니다.
- Bitmap Heap Scan on b (리프 노드)
- Bitmap Index Scan에서 찾은 위치 정보를 바탕으로 b 테이블에서 데이터를 실제로 읽어옵니다.
- 서브쿼리에서 2개의 행을 반환합니다.
- 결과 반환
- a.name과 MAX(score)를 포함한 999개의 행을 반환합니다.
실행계획 분석
- Index Scan on a (리프 노드)
- 목적: a 테이블에서 id < 1000 조건을 만족하는 데이터를 읽어옵니다.
- 동작: a_pkey 인덱스를 사용하여 a 테이블에서 id < 1000 조건을 만족하는 행을 빠르게 찾습니다.
- 비용: cost=0.29..16385.98
- 0.29: 인덱스 스캔을 시작하는 비용
- 16385.98: a 테이블에서 조건에 맞는 데이터를 전부 스캔하는 예상 비용
- 실제 시간: actual time=0.102..10.680
- 0.102 ms: 인덱스 스캔을 시작한 후 첫 번째 행을 읽는 데 걸린 시간
- 10.680 ms: 전체 인덱스 스캔이 완료되는 데 걸린 시간
- 행 수: rows=999
- id < 1000 조건을 만족하는 999개의 행이 반환되었습니다.
- SubPlan 1 (서브쿼리 부분)
- 목적: a.id와 일치하는 b.a_id에 대한 MAX(score) 값을 계산합니다.
- 동작: 각 a 테이블의 행에 대해 서브쿼리로 b 테이블에서 a_id = a.id인 조건을 만족하는 데이터에서 MAX(score) 값을 구합니다.
- 비용: cost=16.01..16.02
- 16.01: 서브쿼리의 초기 비용
- 16.02: 서브쿼리 완료 후 최종적으로 값을 계산하는 비용
- 실제 시간: actual time=0.009..0.010
- 서브쿼리의 계산은 빠르게 이루어졌으며, 각 반복에서 약 0.009 ms에서 0.010 ms가 소요되었습니다.
- 반복 횟수: loops=999
- a 테이블에서 999번 반복하며 서브쿼리를 실행합니다.
- Bitmap Heap Scan on b (리프 노드)
- 목적: b 테이블에서 a.id = b.a_id 조건을 만족하는 데이터를 찾습니다.
- 동작: Bitmap Index Scan으로 찾은 위치 정보를 기반으로 실제 데이터를 읽어옵니다.
- 비용: cost=4.44..16.01
- 4.44: Bitmap Index Scan을 통해 b 테이블에서 데이터를 찾는 비용
- 16.01: Bitmap Heap Scan으로 실제 데이터를 읽는 비용
- 실제 시간: actual time=0.006..0.008
- 0.006 ms: 첫 번째 힙 데이터 읽기 시작 시간
- 0.008 ms: 전체 데이터를 읽는 데 걸린 시간
- 행 수: rows=2
- 서브쿼리에서 조건을 만족하는 b 테이블의 데이터 2개가 반환되었습니다.
- Bitmap Index Scan on idx_b_aid (리프 노드)
- 목적: b 테이블에서 a_id = a.id 조건을 만족하는 행을 찾기 위해 인덱스를 사용합니다.
- 동작: 인덱스를 사용하여 a_id = a.id 조건을 만족하는 b 테이블의 데이터를 찾습니다.
- 비용: cost=0.00..4.44
- 0.00: 인덱스를 스캔하는 데 드는 비용
- 4.44: 인덱스를 사용하여 b 테이블에서 데이터를 찾는 비용
- 실제 시간: actual time=0.003..0.003
- 0.003 ms: 인덱스 검색을 시작한 후 첫 번째 결과를 찾는 데 걸린 시간
- 행 수: rows=2
- a_id = a.id 조건을 만족하는 b 테이블의 데이터 2개가 반환되었습니다.
- Planning
- Planning Time: 0.367 ms
- 쿼리 계획을 수립하는 데 걸린 시간은 0.367 ms입니다.
- Planning Time: 0.367 ms
- Execution Time: 10.872 ms
- 전체 쿼리 실행에 소요된 시간은 약 10.872 ms입니다.
- LATERAL
EXPLAIN ANALYZE
SELECT a.name, b_max.max_score
FROM a
JOIN LATERAL (
SELECT MAX(score) AS max_score FROM b WHERE b.a_id = a.id
) b_max ON TRUE
WHERE a.id < 1000;
흐름
- Index Scan on a (리프 노드)
- a_pkey 인덱스를 사용하여 a.id < 1000 조건을 만족하는 데이터를 찾습니다.
- 999개의 행이 반환됩니다.
- Subquery (LATERAL JOIN)
- 각 a.id에 대해 서브쿼리를 실행하여 b.a_id = a.id 조건을 만족하는 데이터에서 MAX(score) 값을 계산합니다.
- Bitmap Index Scan on b (리프 노드)
- a.id와 일치하는 b.a_id 값을 찾기 위해 인덱스를 사용하여 데이터를 찾습니다.
- b.a_id = a.id 조건을 만족하는 b 테이블의 데이터 2개가 반환됩니다.
- Bitmap Heap Scan on b (리프 노드)
- Bitmap Index Scan에서 찾은 위치 정보를 바탕으로 실제 데이터를 읽어옵니다.
- 조건을 만족하는 b 테이블의 데이터 2개를 반환합니다.
- Nested Loop
- a 테이블의 각 행에 대해 서브쿼리(MAX(score))를 실행하여 결과를 결합합니다.
- 결과 반환
- a.name과 MAX(score) 값을 포함한 999개의 행이 반환됩니다.
실행계획 분석
- Index Scan on a (리프 노드)
- 목적: a_pkey 인덱스를 사용하여 a.id < 1000 조건을 만족하는 데이터를 빠르게 찾습니다.
- 동작: a 테이블에서 id < 1000 조건을 만족하는 행을 찾기 위해 a_pkey 인덱스를 사용하여 빠르게 탐색합니다.
- 비용: cost=0.29..41.14
- 0.29: 인덱스 스캔을 시작하는 비용
- 41.14: a 테이블에서 조건을 만족하는 데이터를 전부 스캔하는 비용
- 실제 시간: actual time=0.047..0.530
- 0.047 ms: 인덱스 스캔을 시작한 후 첫 번째 행을 읽는 데 걸린 시간
- 0.530 ms: 전체 인덱스 스캔이 완료되는 데 걸린 시간
- 행 수: rows=999
- id < 1000 조건을 만족하는 999개의 행이 반환되었습니다.
- Nested Loop (루프 동작)
- 목적: a 테이블의 각 행에 대해 서브쿼리 (JOIN LATERAL)를 실행합니다.
- 동작: a 테이블에서 반환된 각 행에 대해, b 테이블에서 a.id = b.a_id 조건을 만족하는 데이터에서 MAX(score) 값을 계산하여 결합합니다.
- 비용: cost=16.31..16396.18
- 16.31: a 테이블의 인덱스 스캔 및 서브쿼리 실행을 포함한 초기 비용
- 16396.18: 전체 쿼리 실행 후 예상되는 비용
- 실제 시간: actual time=0.083..11.865
- 0.083 ms: Nested Loop이 시작된 시점에서 첫 번째 행을 찾는 데 걸린 시간
- 11.865 ms: 전체 Nested Loop 실행이 완료되는 데 걸린 시간
- 행 수: rows=999
- 999개의 행이 최종 결과로 반환되었습니다.
- Aggregate (서브쿼리 처리)
- 목적: b 테이블에서 a.id와 일치하는 b.a_id 조건을 만족하는 행의 MAX(score) 값을 구합니다.
- 동작: b.a_id = a.id 조건에 맞는 데이터를 찾아 MAX(score) 값을 계산합니다.
- 비용: cost=16.01..16.02
- 16.01: 서브쿼리의 초기 비용
- 16.02: 서브쿼리가 끝날 때까지의 총 비용
- 실제 시간: actual time=0.010..0.010
- 각 서브쿼리 계산에 소요된 시간은 약 0.010 ms로 매우 빠르게 처리되었습니다.
- 반복 횟수: loops=999
- a 테이블에서 999번 반복하여 서브쿼리를 실행합니다.
- Bitmap Heap Scan on b (리프 노드)
- 목적: b 테이블에서 a.id = b.a_id 조건을 만족하는 데이터를 찾습니다.
- 동작: Bitmap Index Scan으로 찾은 위치 정보를 기반으로 실제 데이터를 읽어옵니다.
- 비용: cost=4.44..16.01
- 4.44: Bitmap Index Scan을 통해 b 테이블에서 데이터를 찾는 비용
- 16.01: Bitmap Heap Scan으로 실제 데이터를 읽는 비용
- 실제 시간: actual time=0.006..0.009
- 0.006 ms: 첫 번째 힙 데이터를 읽는 데 걸린 시간
- 0.009 ms: 전체 데이터를 읽는 데 걸린 시간
- 행 수: rows=2
- b 테이블에서 조건을 만족하는 2개의 행이 반환되었습니다.
- Heap Blocks: exact=1999
- b 테이블에서 1999개의 정확한 힙 블록이 사용되었습니다.
- Bitmap Index Scan on idx_b_aid (리프 노드)
- 목적: b 테이블에서 a.id와 일치하는 b.a_id 값을 찾기 위해 인덱스를 사용합니다.
- 동작: 인덱스를 사용하여 a.id = b.a_id 조건을 만족하는 b 테이블의 데이터를 찾습니다.
- 비용: cost=0.00..4.44
- 0.00: 인덱스를 스캔하는 데 드는 비용
- 4.44: 인덱스를 사용하여 b 테이블에서 데이터를 찾는 비용
- 실제 시간: actual time=0.003..0.003
- 0.003 ms: 인덱스 검색을 시작한 후 첫 번째 결과를 찾는 데 걸린 시간
- 행 수: rows=2
- a.id = b.a_id 조건을 만족하는 b 테이블의 데이터 2개가 반환되었습니다.
- Planning
- Planning Time: 0.428 ms
- 쿼리 계획을 수립하는 데 걸린 시간은 0.428 ms입니다.
- Planning Time: 0.428 ms
- Execution Time: 12.059 ms
- 전체 쿼리 실행에 소요된 시간은 약 12.059 ms입니다.
5. SQL 튜닝 기법
- 인덱스 전략
- WHERE / JOIN / ORDER BY에 자주 등장하는 컬럼 인덱스화
- 불필요한 인덱스는 제거 (쓰기 비용 증가)
- 복합 인덱스: WHERE + ORDER BY 최적화 가능
- 통계 정보
- ANALYZE를 수동으로 수행하거나 autovacuum 설정으로 관리
- 통계가 부정확하면 옵티마이저가 잘못된 실행계획을 선택
- 메모리 설정
- work_mem: 정렬, 해시조인 등의 처리에 사용됨. 초과 시 디스크 사용
- shared_buffers: 전체 PostgreSQL 인스턴스에서 공유하는 버퍼 캐시
- 병렬 쿼리 활용
- max_parallel_workers_per_gather: 병렬로 데이터 처리 가능
- parallel_tuple_cost, parallel_setup_cost 조정으로 병렬 사용 유도
- 조인 방식 선택
- 작은 테이블 + 인덱스: Nested Loop
- 중간 크기 테이블: Hash Join
- 정렬된 조인 키 또는 인덱스: Merge Join
Chapter 14. Performance Tips
Chapter 14. Performance Tips Table of Contents 14.1. Using EXPLAIN 14.1.1. EXPLAIN Basics 14.1.2. EXPLAIN ANALYZE 14.1.3. Caveats 14.2. Statistics Used by …
www.postgresql.org
50.5. Planner/Optimizer
50.5. Planner/Optimizer # 50.5.1. Generating Possible Plans The task of the planner/optimizer is to create an optimal execution plan. A given …
www.postgresql.org
Tuning Your PostgreSQL Server - PostgreSQL wiki
by Greg Smith, Robert Treat, and Christopher Browne PostgreSQL ships with a basic configuration tuned for wide compatibility rather than performance. Odds are good the default parameters are very undersized for your system. Rather than get dragged into the
wiki.postgresql.org
그냥 많이 보고 눈에 익히는 게 좋습니다.
오늘은 여기까지~
'PostgreSQL' 카테고리의 다른 글
| PostgreSQL: ROLE (4) | 2025.06.09 |
|---|---|
| PostgreSQL: 병렬 INSERT가 되지 않는 이유 (1) | 2025.06.08 |
| PostgreSQL: postgres_fdw vs dblink (0) | 2025.05.28 |
| PostgreSQL: work_mem (0) | 2025.05.27 |
| PostgreSQL: Disk Spill (0) | 2025.05.26 |